FCN笔记(Fully Convolutional Networks for Semantic Segmentation)
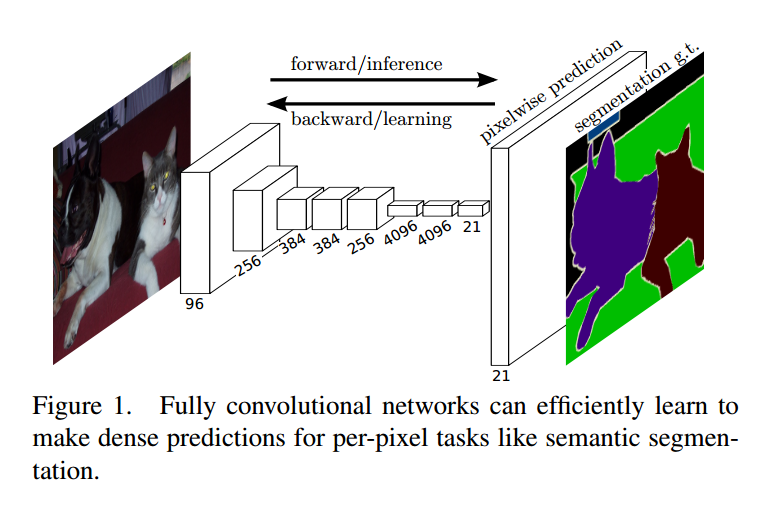
(1)FCN做的主要操作
(a)将之前分类网络的全连接层都换成卷积层;
FCN将全连接层换成了卷积层,形成一个全卷积网络,最后生成一个heatmap。卷积层的大小即为 (1,1,4096)、(1,1,4096)、(1,1,1000)。FCN在做前向和后向计算时,都比之前的方法要快,FCN生成一个10*10的结果,需要22ms,而之前的方法生个1个结果,就需要1.2ms,如果是100个结果,就需要120ms,所以FCN更快。使用了全卷积层之后,对输入图片的规格大小就没有要求了。
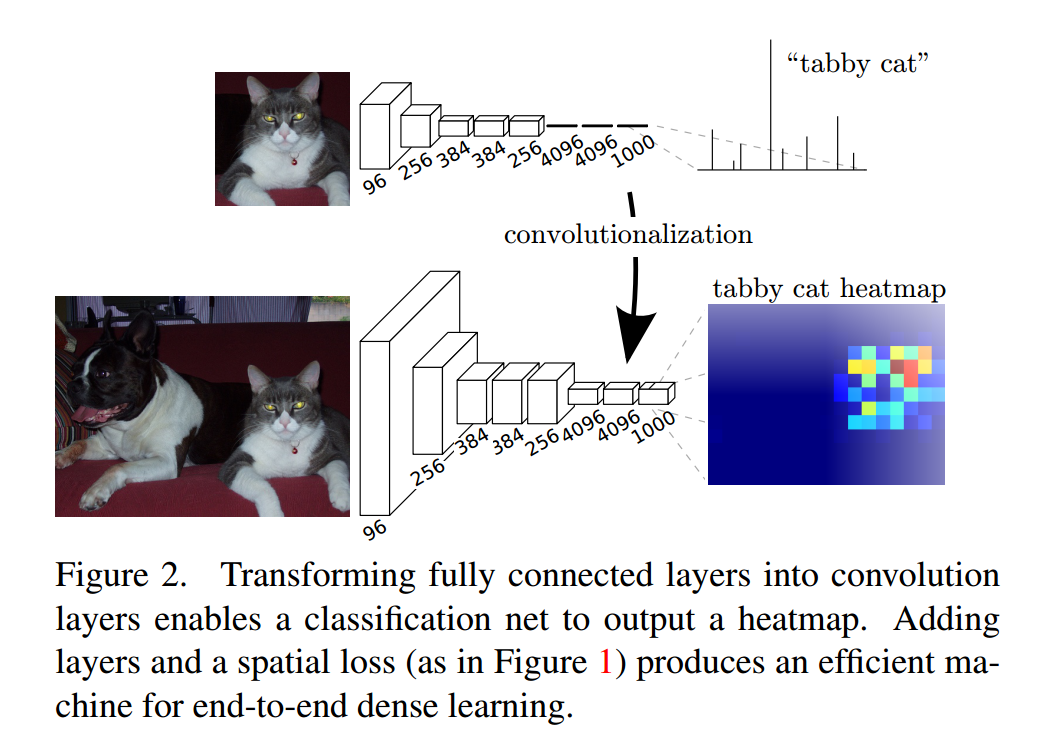
(b)使用上采样操作;
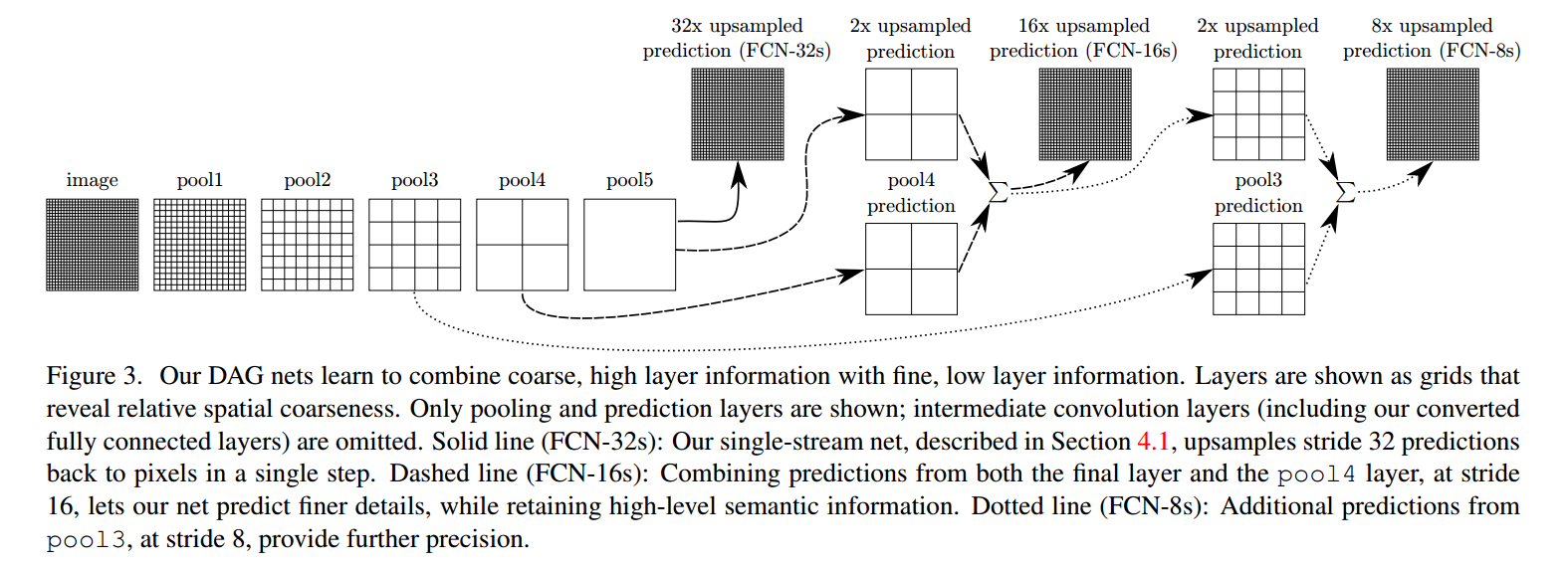
(c)并且将这些特征图进行上采样之后,将特征图对应元素相加;
因为经过多次卷积和pooling之后,得到的图像越来越小,分辨率越来越低,FCN为了得到信息,使用上采样(使用deconvolution)实现尺寸还原。不仅对pool5之后的特征图进行了还原,也对pool4和pool3之后的特征图进行了还原,结果表明,从这些特征图能很好的获得关于图片的语义信息,而且随着特征图越来越大,效果越来越好。
(2)语义分割中的评价指标

pa:是标记正确的像素占总像素的比例
mpa:每个类别被正确分类像素的比例,之后求所有类的平均
mIU:在每个类上求IoU,再求平均
fwIU:根据每个类出现的频率为其设置权重,再算IoU
关于patch wise training and fully convolutional training
The term "Fully Convolutional Training" just means replacing fully-connected layer with convolutional layers so that the whole network contains just convolutional layers (and pooling layers).
The term "Patchwise training" is intended to avoid the redundancies of full image training. In semantic segmentation, given that you are classifying each pixel in the image, by using the whole image, you are adding a lot of redundancy in the input. A standard approach to avoid this during training segmentation networks is to feed the network with batches of random patches (small image regions surrounding the objects of interest) from the training set instead of full images. This "patchwise sampling" ensures that the input has enough variance and is a valid representation of the training dataset (the mini-batch should have the same distribution as the training set). This technique also helps to converge faster and to balance the classes. In this paper, they claim that is it not necessary to use patch-wise training and if you want to balance the classes you can weight or sample the loss. In a different perspective, the problem with full image training in per-pixel segmentation is that the input image has a lot of spatial correlation. To fix this, you can either sample patches from the training set (patchwise training) or sample the loss from the whole image. That is why the subsection is called "Patchwise training is loss sampling". So by "restricting the loss to a randomly sampled subset of its spatial terms excludes patches from the gradient computation." They tried this "loss sampling" by randomly ignoring cells from the last layer so the loss is not calculated over the whole image.
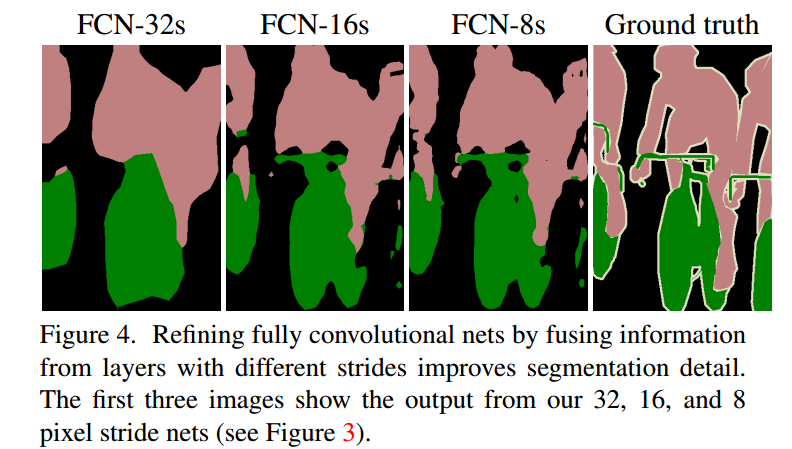
最后的效果
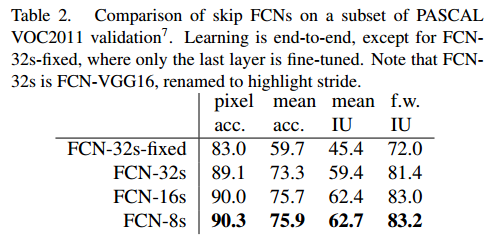

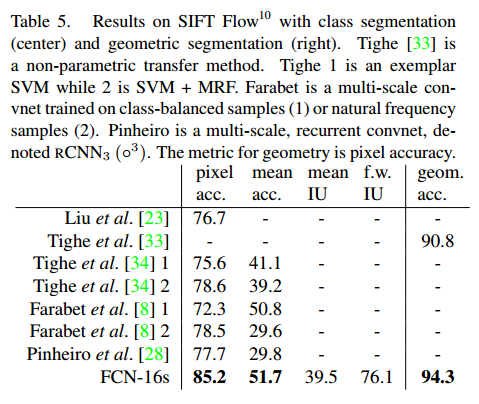

缺点()
在这里我们要注意的是FCN的缺点:
- 是得到的结果还是不够精细。进行8倍上采样虽然比32倍的效果好了很多,但是上采样的结果还是比较模糊和平滑,对图像中的细节不敏感。
- 是对各个像素进行分类,没有充分考虑像素与像素之间的关系。忽略了在通常的基于像素分类的分割方法中使用的空间规整(spatial regularization)步骤,缺乏空间一致性。